
On July 19, 2024, cybersecurity technology provider CrowdStrike released a configuration update to its Falcon software for Microsoft Windows systems. This update triggered an error that resulted in a system crash that impacted hospitals, airlines, banks, governments, and multiple enterprises. The global cost of the IT outage caused by CrowdStrike is expected to be tens of billions of dollars, if not hundreds of billions of dollars.
There are multiple ways to think about the CrowdStrike IT outage and how we can prevent similar incidents in the future. Certainly, the outage was a software problem that required a software solution. But we must also consider this incident as a process problem that requires process solutions.
Note: CrowdStrike released a preliminary report1 on July 24, 2024. We are working on an update to capture this additional information.
The CrowdStrike IT Outage as a Software Problem
Organizations use CrowdStrike’s Falcon on Windows to protect computers from viruses and other malware. Falcon is installed as a boot-start driver, which means that Microsoft Windows needs this software to run successfully to boot into normal state.
Normal Startup and Restart Processes with CrowdStrike for Microsoft
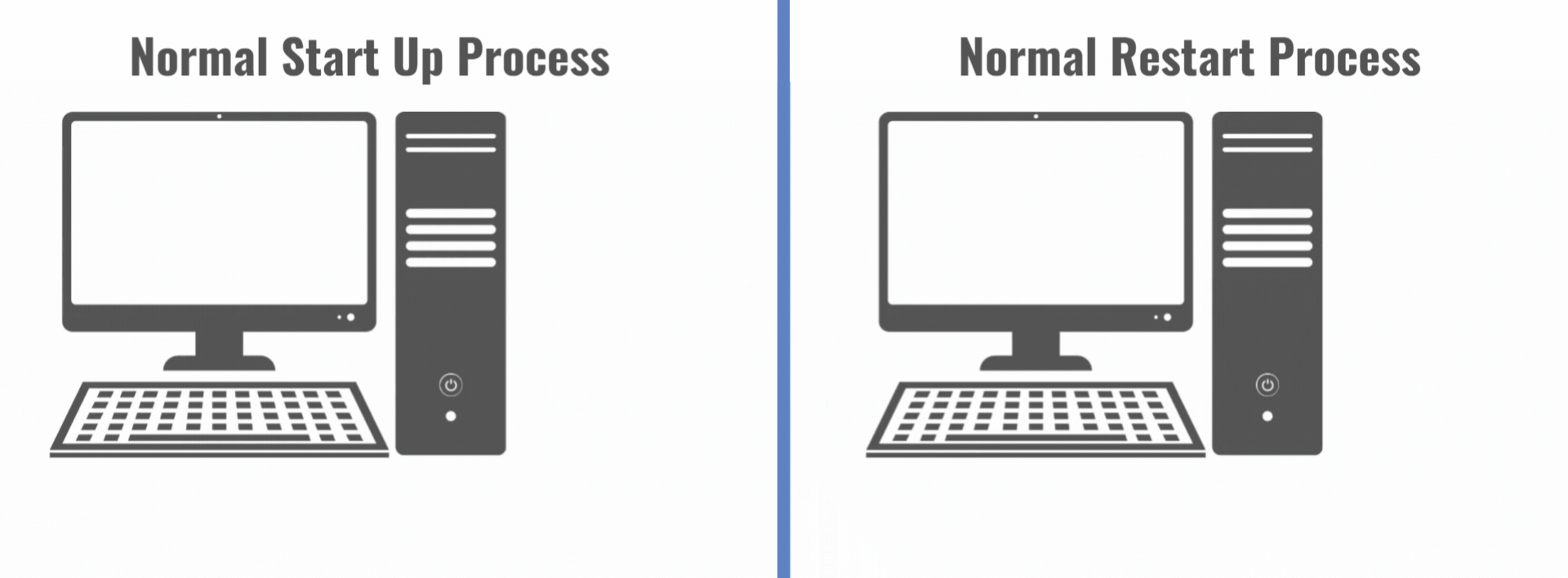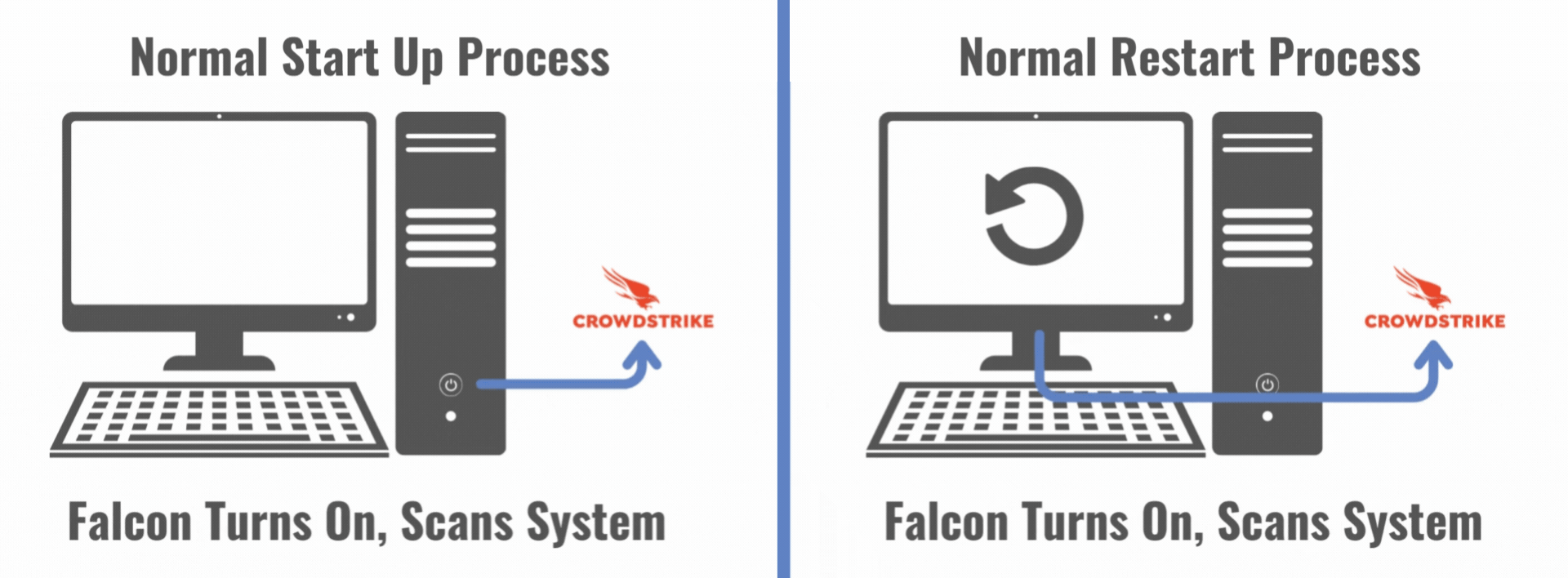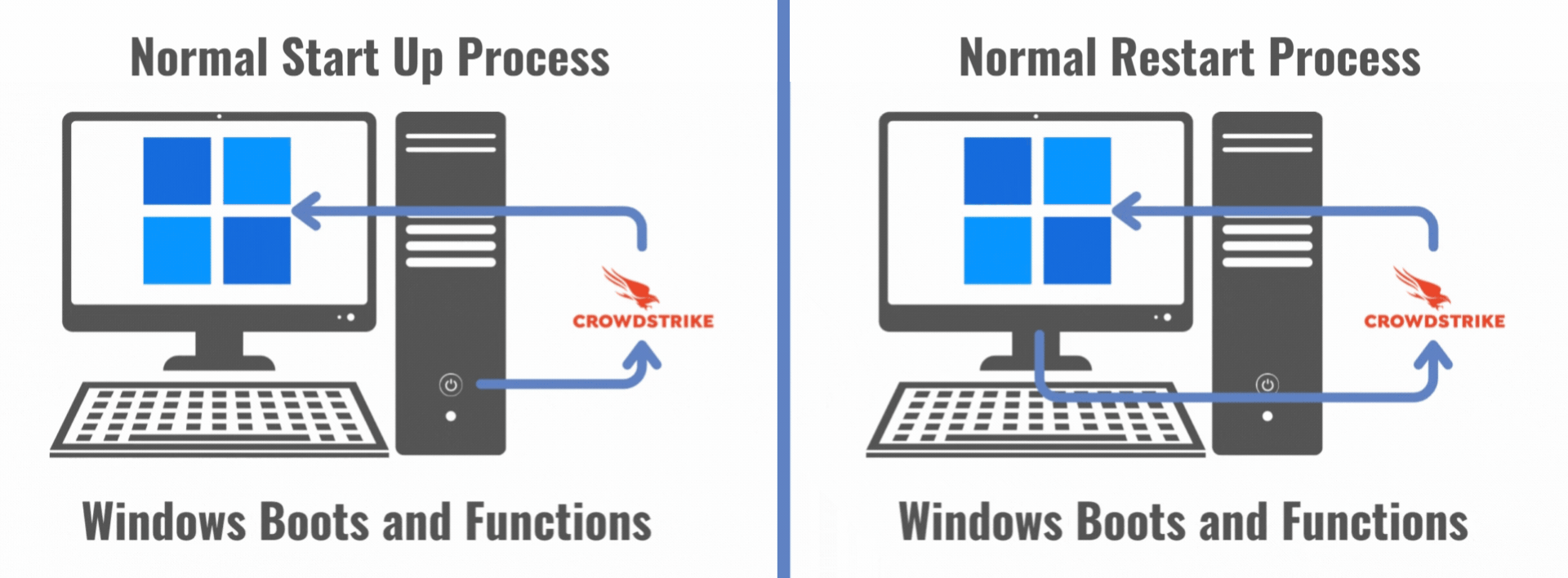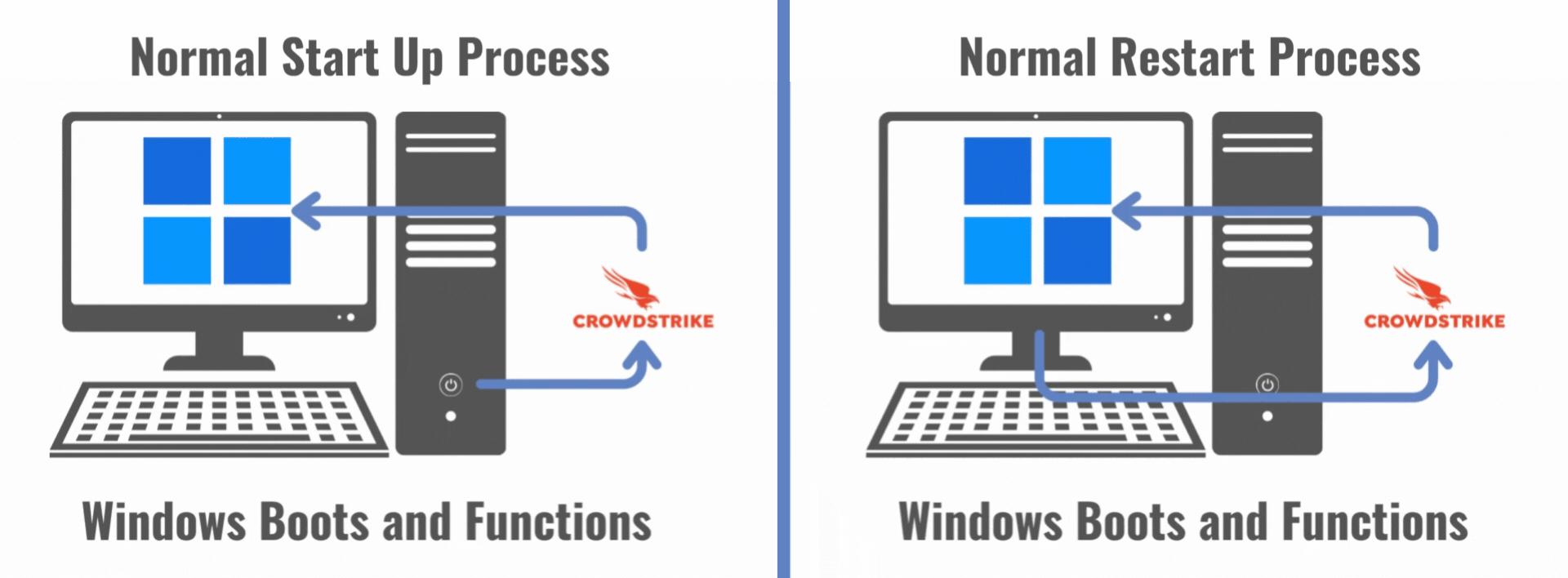
Cybersecurity providers like CrowdStrike frequently deploy software updates to keep their clients protected from ever-evolving cyber threats. Many cybersecurity clients turn on auto-updates to ensure their computers have the most up-to-date protections in place. On July 19, 2024, at 4:09 UTC (12:09 AM EDT), CrowdStrike deployed an updated configuration (config) file per its normal operating procedures, and this file was automatically installed on millions of computers around the world, just like many previous updates. It was all business as usual, except this file was defective.
The problems with the July 19 configuration file update are technical and still under investigation, so we’ll describe what happened at a high level. In a nutshell, as the Falcon software connected to the network, the configuration file update triggered an error with the Falcon software. The Falcon software error triggered a Windows core fault resulting in a Windows operating system crash and subsequent restart. But because Falcon is installed as a boot-start driver in Windows and the software is constantly communicating, this error creates an endless loop of the computer restarting.
Boot Loop Caused by Defective File
.gif)
CrowdStrike released an update to the defective file at 5:27 UTC (just over an hour after the defective file was released), but millions of computers were already stuck in the boot loop above.
The solution to the restart loop problem is deceptively simple: delete the defective configuration file. But to delete the file, each computer or system needs to be restarted in safe mode by an administrator. In other words, the files need to be deleted manually by human beings. That’s why the process of fixing the outage took days, even though the defective file was only released for about one hour.
The CrowdStrike IT Outage as a Process Problem
As a software problem, the CrowdStrike IT outage has an easy (albeit time-consuming) solution. However, given the frequency of cybersecurity updates, which are necessary to keep up with evolving cyber threats, removing one defective file will not be enough to prevent future outages. We need to dig deeper to understand the process breakdowns that allowed one bad file to cascade into a multi-billion-dollar problem.
We’ll start with a simple 5-Why Cause Map™ diagram, focusing on the incident’s impact on production. Production was negatively impacted by a total loss of more than $10 billion dollars across industries. Revenue was lost due to extended outages, and these outages were due to computers not functioning. Computers could not function because they could not enter Windows, and computers could not enter Windows due to the deployment of the defective configuration file.
CrowdStrike IT Outage 5-Why
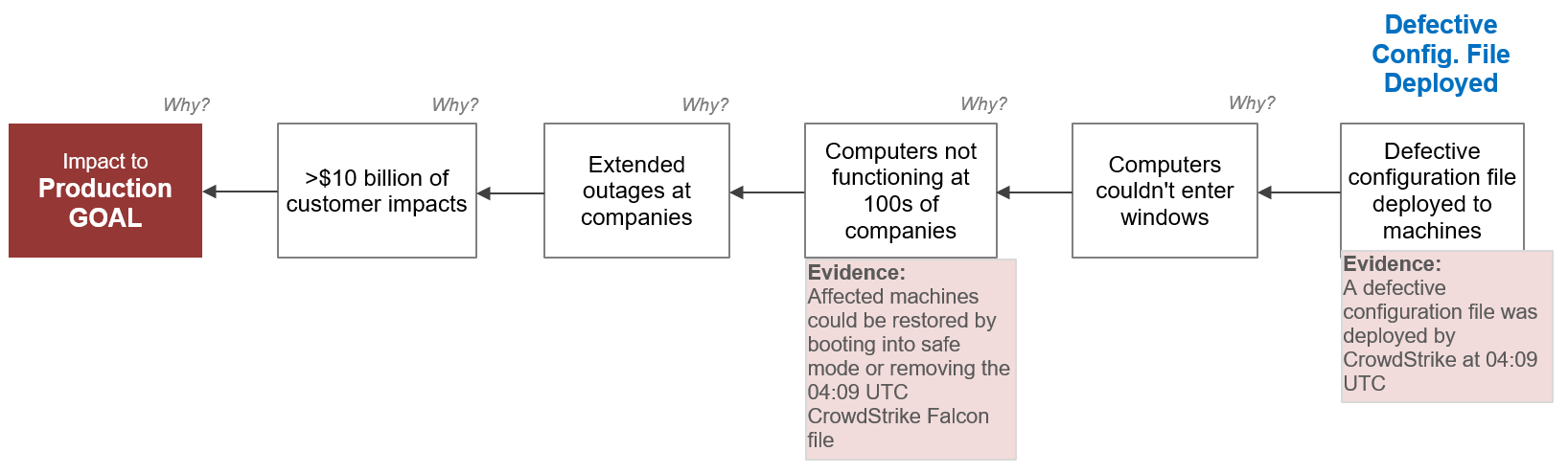
At this point in our analysis, most people would start asking who developed the defective file. It’s true that the developer played a role in the incident, but it’s unwise to pin the blame on this person and stop our analysis here. As VP of Developer Community at Microsoft, Scott Hanselman,2 put it, “It’s always one line of code but it’s NEVER one person.”
For a defective configuration to be deployed, the code had to be developed and that defect had to pass through CrowdStrike’s quality assurance (QA) process. Clearly, neither of these processes went well.
CrowdStrike IT Outage 7-Why
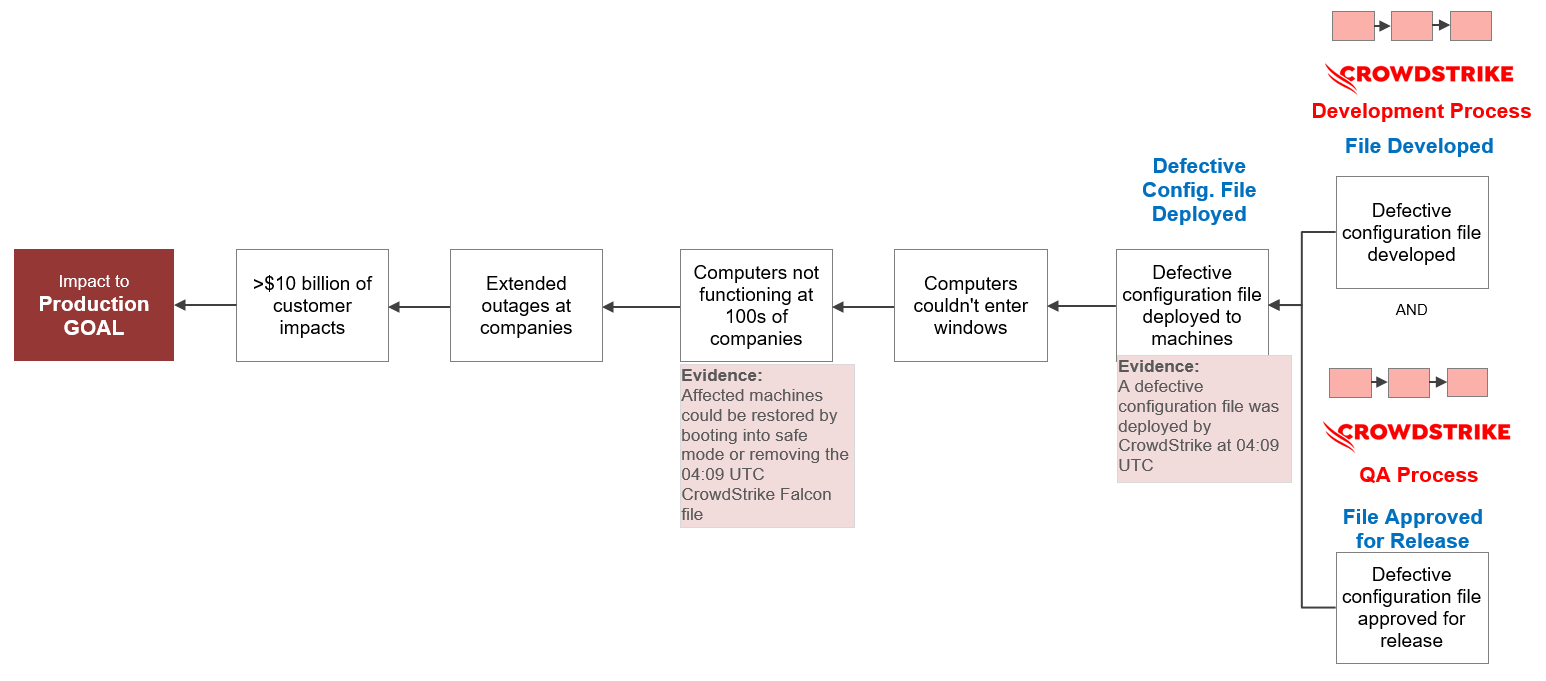
Again, we might be tempted to stop our analysis and shift into blame. CrowdStrike screwed up and it’s all their fault, right? Well, not so fast.
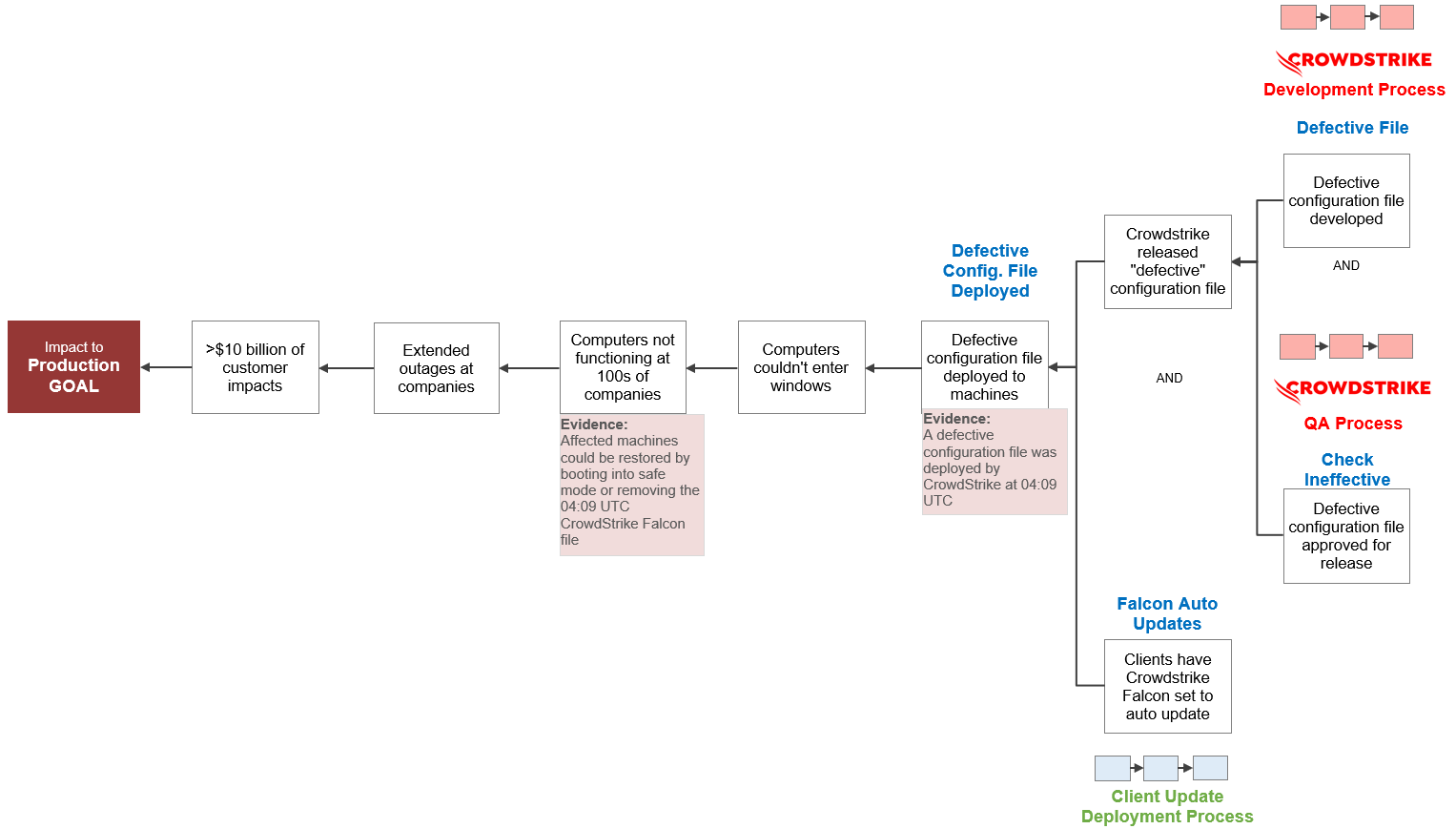
Every company that uses CrowdStrike Falcon chooses how to deploy the software. Companies can choose to update the software automatically, or they can do internal validation testing prior to each deployment in their production environments. If a company chose to do validation testing prior to rollout, they likely would have caught the bug in the configuration file.
As we learned earlier, most companies chose not to do validation testing, instead allowing the software to update automatically. We’ll add this cause and its related process to create the 9-Why below.
CrowdStrike IT Outage 9-Why
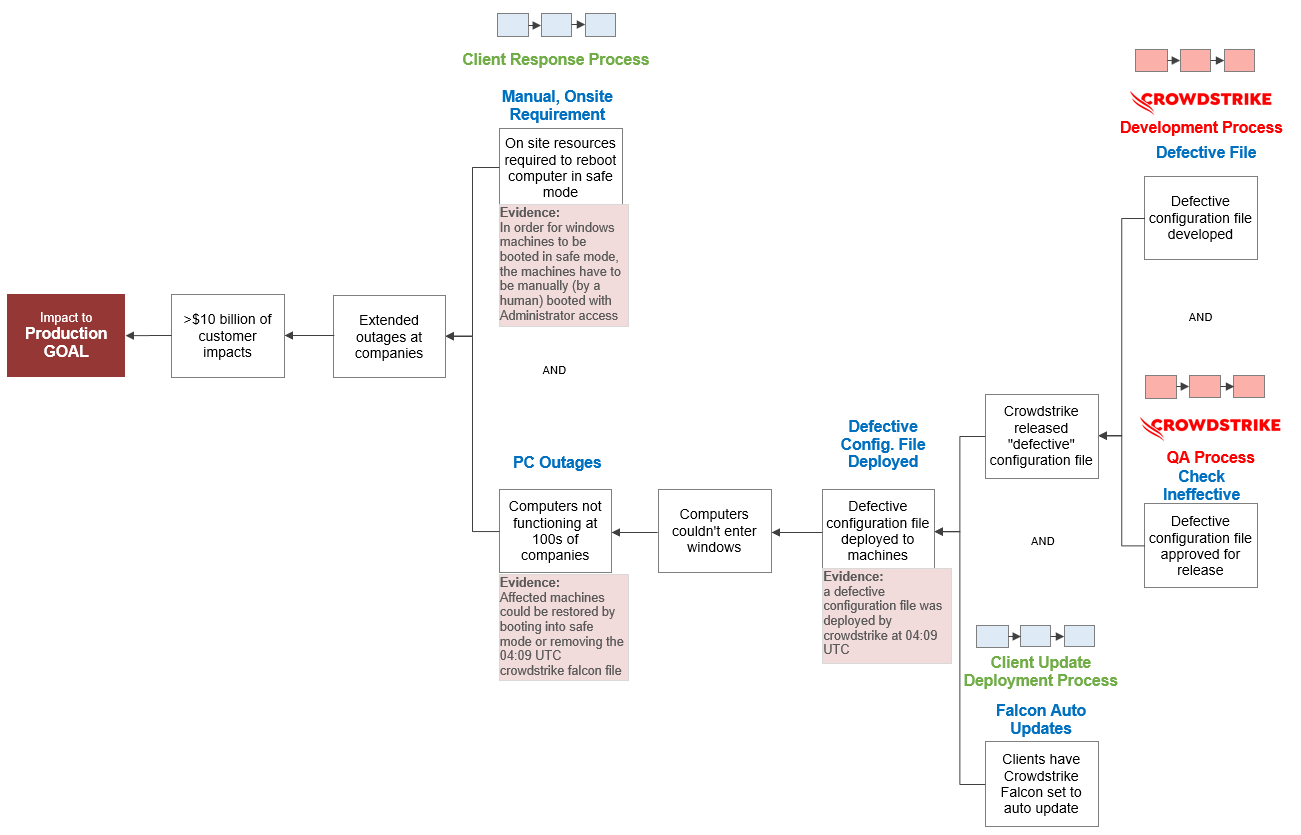
Before we conclude our initial analysis of this incident, let’s add one more important detail. Companies experienced extended outages because computers were not functioning and because computers had to be manually booted in safe mode by an administrator. This process only takes about 30 minutes for one computer. For 8.5 million computers, it takes a lot longer.
CrowdStrike IT Outage 10-Why
What’s Next?
Information about the CrowdStrike IT outage is emerging at a rapid pace, and the response from CrowdStrike (as well as Microsoft) is also evolving. We expect to publish more insights on this incident when more detail is available. Be sure to subscribe to our newsletter so you don’t miss it!

Special thanks to my brother David Dellsperger, Staff Software Engineer at SnapLogic, for his help in understanding this situation. While discussing this situation, he made the following comment which resonated with me:
“While the cause of the config. miss is something an individual made, it's very much a development process—Software Development Lifecycle, SDLC, is the common term for this—that is an additional cause of this situation. While there's a lot of ‘methodologies’ and ‘systems’ in the industry, having a system with robust processes that build in the ability to be agile with changes to that system are key in making long-term fixes.”
1 - Preliminary Report
2 - Scott Hanselman


